Transfer Learning in Genomics¶
Transfer learning is a machine learning paradigm that has become the cornerstone of modern Large Language Models (LLMs), including those used in DNALLM. The core idea is to leverage knowledge gained from solving one problem and apply it to a different but related problem.
1. What is Transfer Learning?¶
In traditional machine learning, models are trained from scratch for each specific task. This requires a large, task-specific labeled dataset and significant computational resources.
Transfer learning revolutionizes this process. It involves two main stages:
-
Pre-training: A large, general-purpose model (a "foundation model") is trained on a massive, broad dataset. The goal of this stage is not to solve a specific task, but to learn general patterns, features, and representations of the data. For LLMs, this means learning grammar, syntax, and semantic relationships.
-
Fine-tuning: The pre-trained model is then adapted to a specific, downstream task using a much smaller, task-specific labeled dataset. Instead of learning from scratch, the model "transfers" its pre-trained knowledge and refines it for the new task.
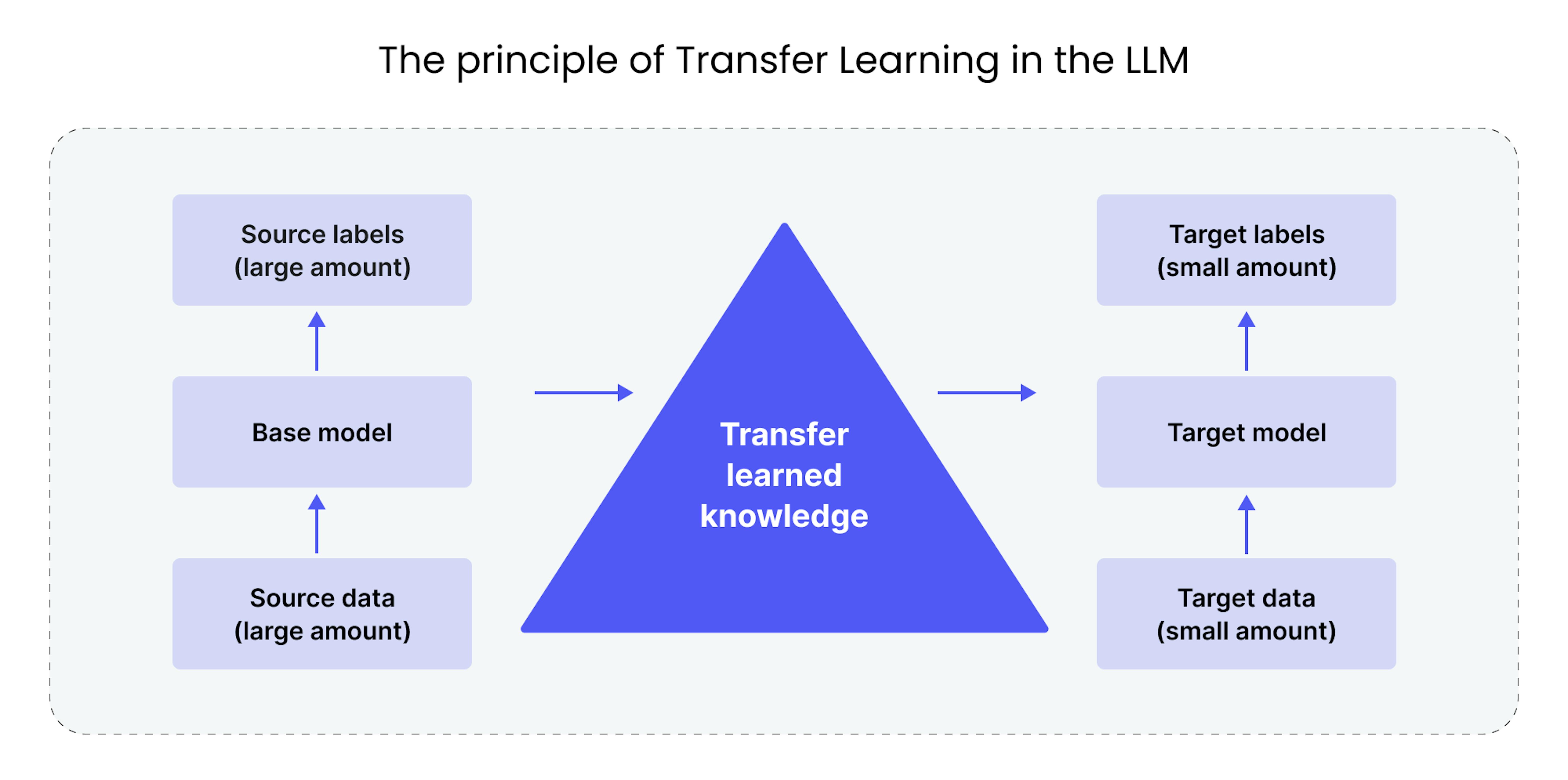 Image Credit: Mad Devs
Image Credit: Mad Devs
2. Transfer Learning and DNA Language Models¶
This two-stage process is perfectly suited for genomics. The "language" of DNA is universal, but its "dialects" (i.e., the functions of specific sequences) are diverse.
Pre-training in DNALLM¶
- The Data: A DNA foundation model like
DNABERTorHyenaDNAis pre-trained on a vast corpus of genomic data, often spanning multiple species (e.g., the entire human reference genome). - The Goal: During this phase, the model learns the fundamental "grammar" of DNA. It learns to recognize common motifs, understand codon structures, and capture long-range dependencies between different parts of a sequence, all without any specific functional labels. This is typically done through self-supervised objectives like Masked Language Modeling (MLM) or Causal Language Modeling (CLM).
Fine-tuning in DNALLM¶
- The Data: You provide a smaller, labeled dataset for a specific biological problem. For example, a CSV file with 5,000 sequences labeled as "promoter" or "not promoter."
- The Goal: The
DNATrainertakes the powerful, pre-trained foundation model and slightly adjusts its weights to specialize it for your task. Because the model already has a deep understanding of DNA structure, it can learn to classify promoters with much less data and in far less time than a model trained from scratch.
3. Why is Transfer Learning so Effective?¶
- Reduced Data Requirement: Fine-tuning requires significantly less labeled data, which is often expensive and time-consuming to acquire in biology.
- Faster Training: Since the model starts with a strong baseline of knowledge, the fine-tuning process converges much faster than training from zero.
- Improved Performance: Foundation models are pre-trained on datasets far larger and more diverse than any single task-specific dataset. This provides a powerful inductive bias, often leading to higher accuracy and better generalization on the downstream task.
By using the models in the Model Zoo, you are directly benefiting from the power of transfer learning. Each model is a repository of generalized biological knowledge, ready to be specialized for your unique research question.
Next: Learn the best practices for adapting these models in Fine-tuning Strategies.